Faster Dashboards with the “Data Extract” Source

Building on Improvements Introduced in v15.2
Back in v15.2 we introduced a new In-Memory Data Processing engine that enabled a tremendous performance and memory usage boost on large datasets with up to tens of millions of rows. You can refer to the blog post we published at that time to learn about the changes and to see the metrics. Improvements included data manipulation on application startup – indexing, sorting, and compression – so it could be faster accessed and would require less memory at runtime. Although it does help while the application is running, there was an opportunity for further optimization, namely how and when this compressed data is prepared.
You see, the preparation phase happened every time the dashboard was opened, which meant slower initial loading time on every application start-up. Web applications suffered from that same slowdown, but for every user session, which also heavily impacted the server’s CPU resources and memory consumption.

Dashboard v16.1 allows you to run data preparation in advance and store the results on a disk in a so-called "data extract" file, which can even be shared between user sessions in a multi-user environment. Technically, you create a new data source – the "Data Extract" source, which can be built on top of any data source type, with the exception of OLAP data binding mode where that kind of optimization would be redundant anyway.

If you’re curious about how data gets compressed, here’s a quick overview. First, all unique column values are indexed and stored in a dictionary. Indexes replace original values and we make sure they take up as few bits as possible. The dictionary and columns with compressed data are then written into the extract source file.
New Metrics: Data Extract Source versus On-Demand Data Preparation
To plot the graphs below, we built a dashboard bound to the Contoso MSSQL Database to display the breakdown of Groups between Categories. In simpler terms, the control needed to group and aggregate about 12 million data rows.
Initial loading time
As you can see below, the initial dashboard loading time in our test environment went down from 48 seconds to only 10 seconds after binding to the Data Extract source.

Memory consumption in web environment
With the Data Extract source, you’ll see an almost entirely flat memory usage graph regardless of the number of users, compared to the regular in-memory data processing where consumption grows proportionally depending on session count.

Create a Data Extract Source with v16.1
To take advantage of these performance benefits, the first step is to run the New Data Source wizard and select Data Extract on the first wizard screen.
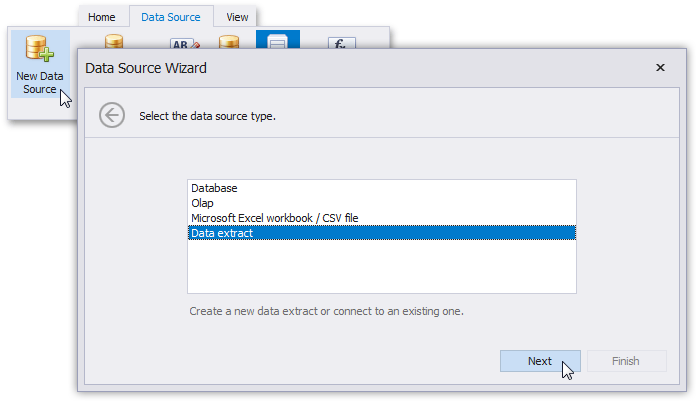
The entire path through the wizard is described in the documentation. When setting up, you have a couple of ways to fine-tune the data source according to your requirements:
- During the initial data source configuration, you can filter out unnecessary data by building custom criteria or by using your data source's parameters.
- You can also adjust the size of the Least Recently Used memory cache, thus balancing memory consumption and frequency of disk reading operations.
Let Us Know What You Think
As always, we'd love to hear from you in the comments section - whether you have questions about this new functionality or feedback on how these improvements worked in your projects.
Free DevExpress Products - Get Your Copy Today
 Vladimir Abadzhev (DevExpress)
Vladimir Abadzhev (DevExpress)