XPO 6.1 introduces a number of changes that do a lot for its support of distributed applications. This is going to be the first in a series of posts around the topic of distributed applications involving XPO. I hope I can shed some light on the structures we provide in XPO for this purpose and the scenarios in which various platforms like .NET Remoting, XML Web Services and Windows Communication Foundation (WCF) can be used in conjunction with XPO.
As always, please feel free to comment on these posts as much as possible – at some point, I might summarize all the information in a more formal technical article, and it would be good to have as many different perspectives in there as possible.
So why does XPO work together well with distributed systems in general? The answer to this question requires some knowledge about the architectural requirements of a performant setup of such systems, as well as about the new layered structure of XPO’s inner workings.
Making distributed systems perform well
To make distributed systems perform well, we should make sure that as little data as possible is transferred over the wire. (Depending on his/her definition of “performing well”, the programmer might also give some thought to topics like platform and/or protocol independence, but that’s not what I’m talking about here.) To make as little data go over the wire as possible, it is important to define those interfaces that are called remotely very efficiently. This means two things:
- The data that is being transferred must be structured specifically for this purpose.
- The structure of the application, and the interface itself, must be designed in such a way that calls to the remote interfaces are minimized.
The result of this will be an interface that’s coarse-grained and that works with data types different from those that are being used on either side of the communication.
So what does XPO do in this regard?
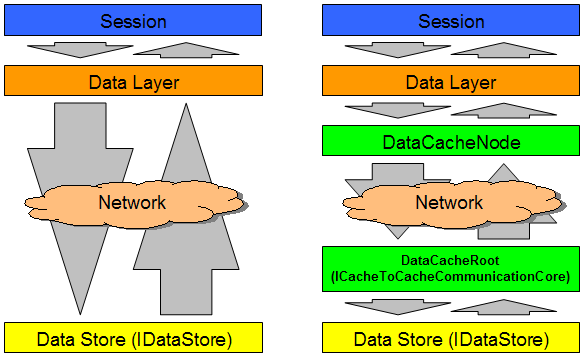
XPO defines two different interfaces that are structured in the way described above: IDataStore and ICacheToCacheCommunicationCore.
This is how IDataStore is defined:
public interface IDataStore {
AutoCreateOption AutoCreateOption { get; }
ModificationResult ModifyData(params ModificationStatement[] dmlStatements);
SelectedData SelectData(params SelectStatement[] selects);
UpdateSchemaResult UpdateSchema(bool dontCreateIfFirstTableNotExist, params DBTable[] tables);
}
As you can see, the data types that are being passed to and returned by these methods are generally (with the exception of the AutoCreateOption enum and the bool primitive data type) not the same that you are used to handling in your own applications, i.e. business objects. They are also not the same that are being handled by your database backend, for example ADO.NET structures or even SQL code. These are data types strictly designed for the purpose of being passed through the IDataStore interface, of course with the idea in mind that the interface may be implemented remotely.
ICacheToCacheCommunicationCore is only minimally bigger than IDataStore:
public interface ICacheToCacheCommunicationCore {
DataCacheModificationResult ModifyData(DataCacheCookie cookie, ModificationStatement[] dmlStatements);
DataCacheResult NotifyDirtyTables(DataCacheCookie cookie, params string[] dirtyTablesNames);
DataCacheResult ProcessCookie(DataCacheCookie cookie);
DataCacheSelectDataResult SelectData(DataCacheCookie cookie, SelectStatement[] selects);
DataCacheUpdateSchemaResult UpdateSchema(DataCacheCookie cookie, DBTable[] tables, bool dontCreateIfFirstTableNotExist);
}
These two interfaces make it possible to cross boundaries to other systems in two places in the layer structure, depending on whether you want to use caching or not.
Free DevExpress Products - Get Your Copy Today
The following free DevExpress product offers remain available. Should you have any questions about the free offers below, please submit a ticket via the
DevExpress Support Center at your convenience. We'll be happy to follow-up.